Data Strategy
Data Strategy
Data Governance
- Data Quality
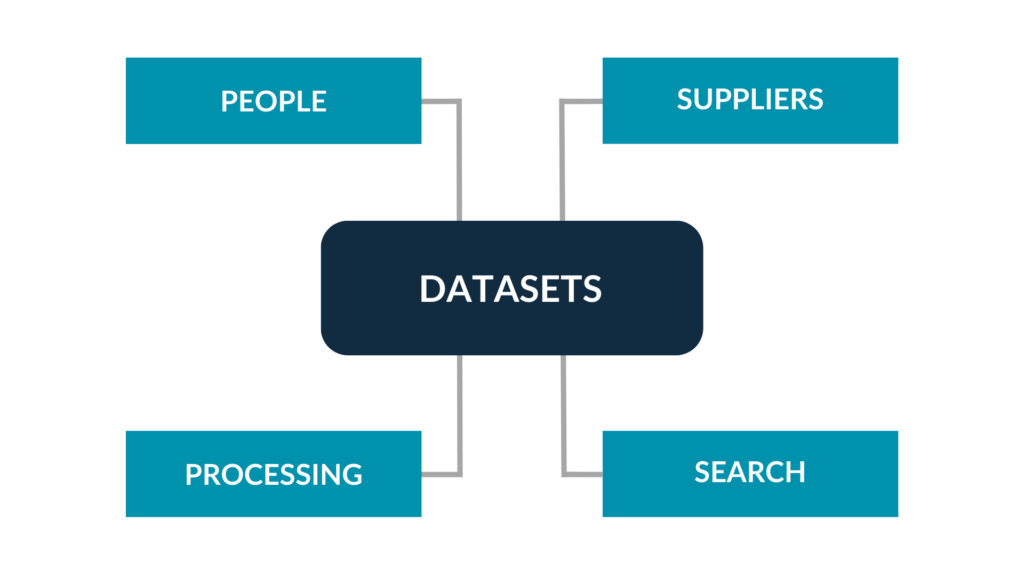
- Data Catalog
Data Platform
Agile BI
Data Driven Company
Hitchhikers Guide to the Data Galaxy®
Data Governance
- Data Quality
- Data Catalog
Data Platform
Agile BI
Data Driven Company
Hitchhikers Guide to the Data Galaxy®
Data Analytics
Visual Analytics
Information Design
Self-Service BI
IBCS konformes Reporting
Reporting
Dashboarding
Sports Analytics
- Sports Analytics mit AWS
Information Design
Self-Service BI
IBCS konformes Reporting
Reporting
Dashboarding
Sports Analytics
- Sports Analytics mit AWS
Cloud Computing
Modern Cloud Data Stack
Cloud Migration
Cloud DWH
Cloud Engineering
Cloud Referenzarchitekturen
Microsoft Azure Cloud Solutions
AWS
- BI & Analytics mit AWS
Multicloud
Cloud Migration
Cloud DWH
Cloud Engineering
Cloud Referenzarchitekturen
Microsoft Azure Cloud Solutions
AWS
- BI & Analytics mit AWS
Multicloud
Operations
Data Platform Operations
Data Infrastructure Op.
Managed Cloud Services
Managed Cloud Applications
Monitoring
Data Infrastructure Op.
Managed Cloud Services
Managed Cloud Applications
Monitoring

Data Engineering
Data Engineering
Cloud Engineering
DevOps Engineering
Data Pipelines
Data Streams
CI/CD
Cloud Engineering
DevOps Engineering
Data Pipelines
Data Streams
CI/CD